La validación de datos cruzados (cross validation en inglés) es una técnica utilizada en el aprendizaje automático para poder evaluar la consistencia de un conjunto de datos y la confiabilidad del modelo con el que se esté entrenando, esta técnica toma como datos de entrada con etiquetas, junto con un modelo de clasificación o regresión no entrenado. Esto quiere decir que se divide el conjunto de datos en varios subconjuntos para que pueda crear un modelo en cada subconjunto con esto determinar un conjunto estadístico de precisión para cada subconjunto. Comparando las estadísticas de presión de todos los subconjuntos se podrá interpretar la calidad de los datos. Luego de todo este proceso se pude determinar si el modelo puede sufrir cambios en los datos.
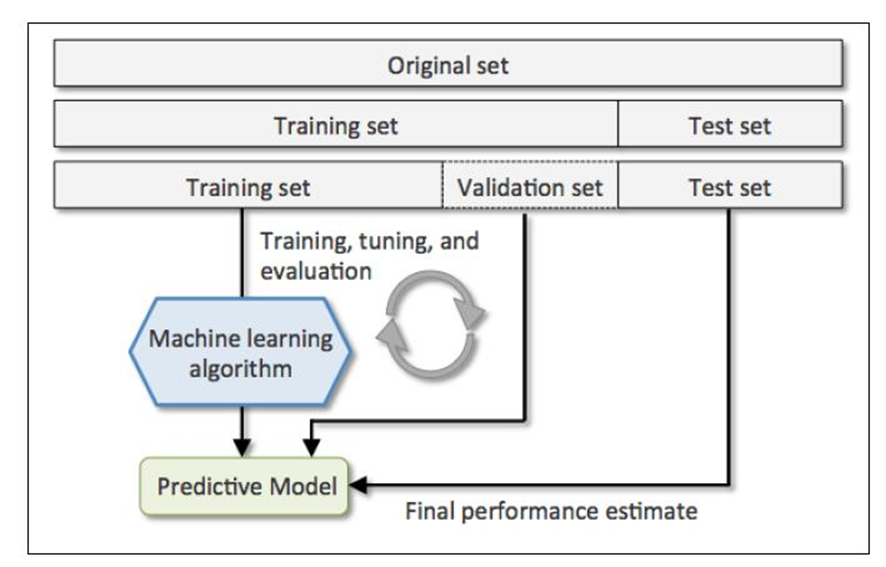
La Validación Cruzada es una técnica de remuestreo con la funcionalidad principal de dividir el conjunto de datos en dos partes, los datos de entrenamiento y los datos de prueba.
Luego del entrenamiento de un modelo de Machine Learning con datos etiquetados, se debería suponer que va a funcionar el algoritmo con nuevos datos, de igual forma se debe tomar en consideración el garantizar la exactitud de las predicciones del modelo.
El modelo de los datos cruzados en su salida evalúa las probabilidades y resultados, por lo tanto, se podrá evaluar la confiabilidad de las predicciones.
En el Machine Learning se usa la validación cruzada para comparar los diferentes modelos y así poder seleccionar el modelo más adecuado para un determinado problema.
La validación de datos cruzados en palabras más simples es una técnica que sirve para evaluar la confiabilidad de nuestros modelos de aprendizaje.
Ejercicio de validación cruzada en conjuntos de datos de dígitos scikit-learn
¿Por qué necesitamos la validación cruzada?
En un supuesto caso se crea un modelo de aprendizaje automático para resolver un problema por lo cuál se entrenó el modelo utilizando un conjunto de datos, al verificar la precisión del modelo en los datos de entrenamiento y se encuentra en un valor cercano a un 95%. ¿Esto significa que el modelo de entrenamiento esta bien y el modelo es el más adecuado por la alta precisión que arroja? No, no lo es debido a que su modelo está entrenando con los datos proporcionado, esto quiere decir que el modelo se entrena con datos muy bien conocidos, captura las variaciones mínimas a esto se le denomina el ruido en los datos y la generalización de los datos proporcionados. Sí en el modelo se expone datos completamente nuevos es posible que no haga una predicción con una buena precisión, para este problema se le llama sobreajuste.
Muchas veces, el modelo NO se entrena bien en el conjunto de entrenamiento porque no puede encontrar patrones, esto quiere decir que tampoco funcionará en los datos de prueba para este problema se le llama ajuste insuficiente.
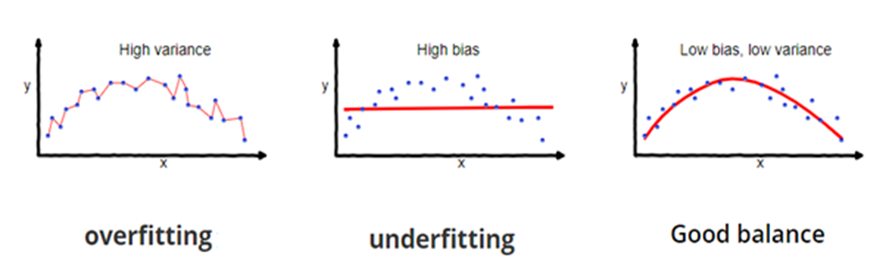
Para solucionar el problema de sobreajuste, se utiliza la técnica de Validación Cruzada.
Cross-Validation: K-fold con 5 splits

EL amarillo muestra para entrenar y el verde muestra el conjunto de validación.
TimeSeriesSplit

EL amarillo muestra para entrenar y el verde muestra el conjunto de validación.
Recomendaciones:
- Tener una proporción de datos para Train y Test en 80/20
- Realizar la técnica de validación cruzada Cross Validation
- Usar Stratified-K-folds en lugar de K-folds.
- La cantidad de “folds” dependerá del tamaño del dataset que tengamos, pero la cantidad usual es 5 (pues es similar al 80-20 que hacemos con train/test).
- Para problemas de tipo time-series usar TimeSeriesSplit
- Si la métrica que usamos (Accuracy) es similar en los conjuntos de Train (donde hicimos Cross Validation) y Test, podemos dar por bueno al modelo.
Una buena practica es unas la validación cruzada en los proyectos, esto nos ayudará a elegir de mejor forma el modelo correcto y se podrá tener una mayor seguridad en la predicción para la toma de decisiones.