EL aprendizaje no supervisado no se puede aplicar directamente a un tipo de regresión o clasificación ya que no se puede determinar los valores de los datos de salida, esto hace que no se pueda entrenar el algoritmo de la forma que se lo realizaría de una manera normal.
El algoritmo de aprendizaje no supervisado permite realizar procesos mas complejos que el aprendizaje supervisado, tomando en cuenta que el aprendizaje sin supervisión es más impredecible en comparación que los métodos de aprendizaje comunes.
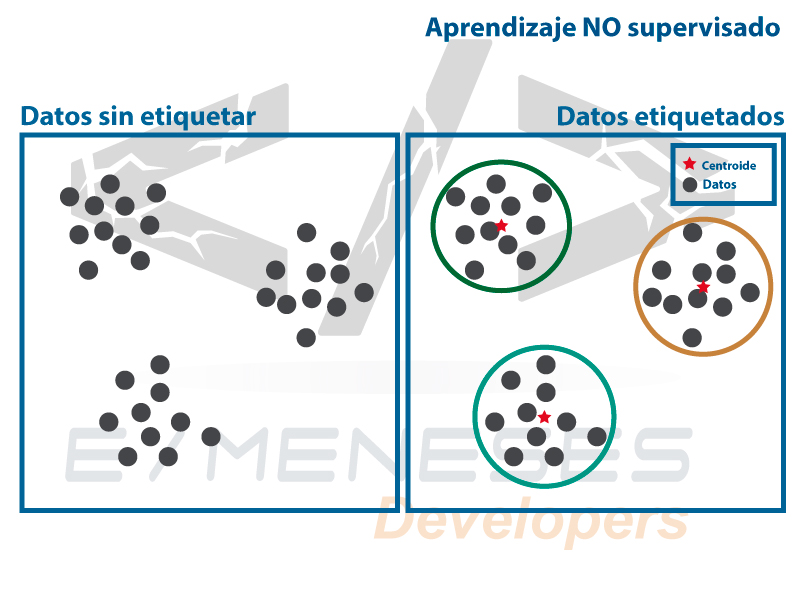
El aprendizaje no supervisado se utiliza para agrupar los datos que no están estructurados esto por sus similitudes y patrones distintos en el conjunto de los datos, esto básicamente es para que los humanos puedan detectar patrones ocultos en los datos.
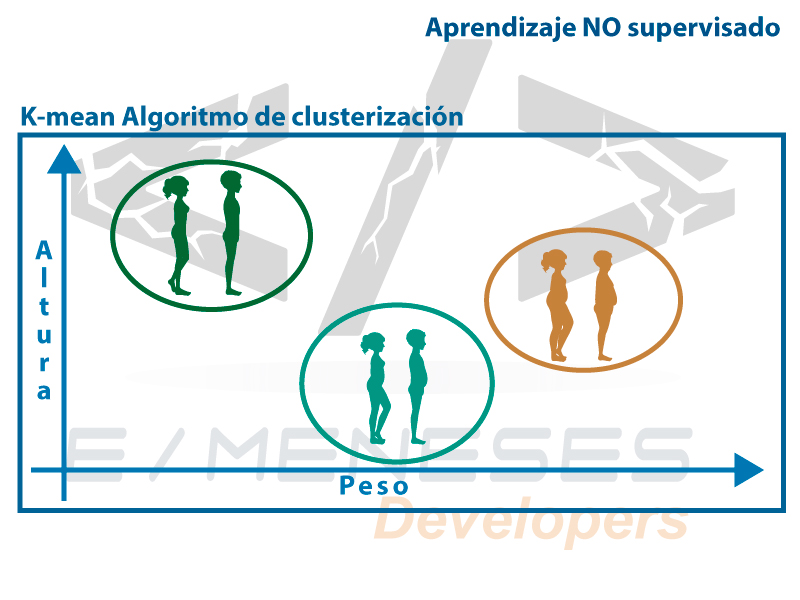
K-means es un algoritmo de Machine learnig de clasificación no supervisada (Clusterización) que agrupa basándose en sus características que tengan en común, esto lo realiza agrupando la suma de distancias que hay entre ellos y el centroide de su grupo también llamado clúster, para esto se suele usar la distancia cuadrática.
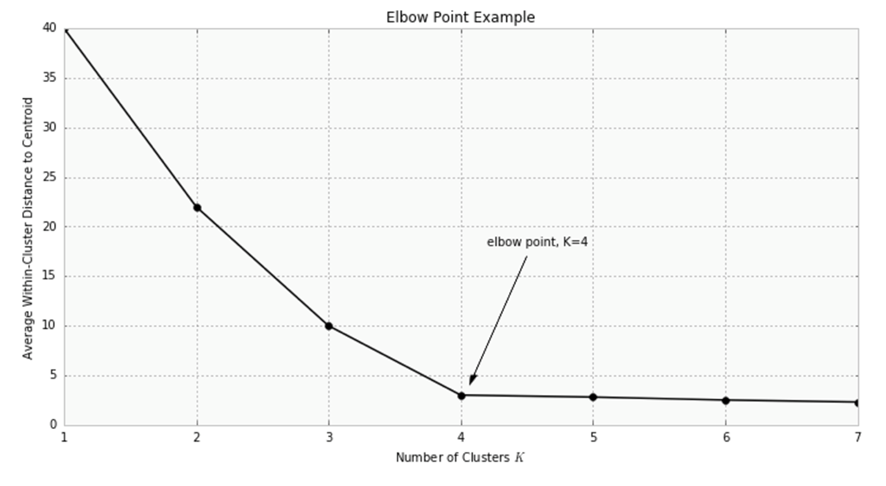
Una de las métricas más usadas para poder comparar los resultados de la distancia media entre los datos y sus centroides, al tener en cuenta esto la medida disminuirá a medida que aumentemos el valor de k, se debe utilizar la distancia media al centroide en función de k y así poder encontrar el “PUNTO CODO”.
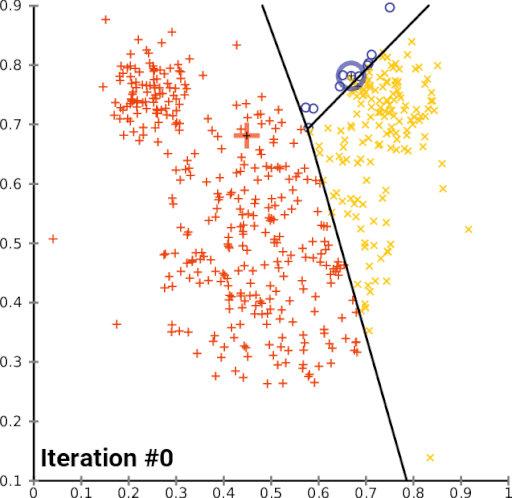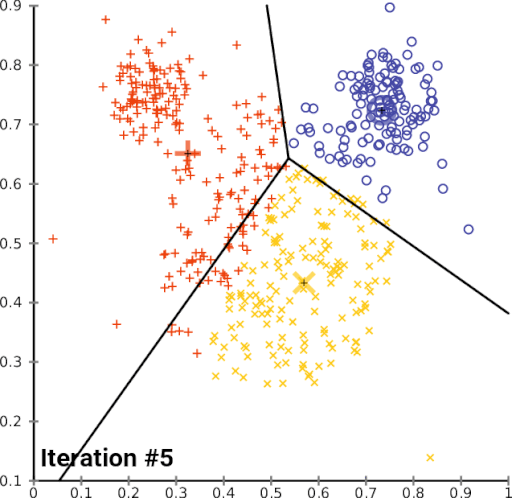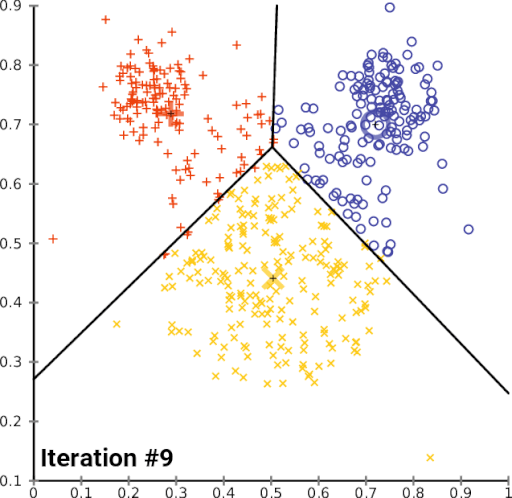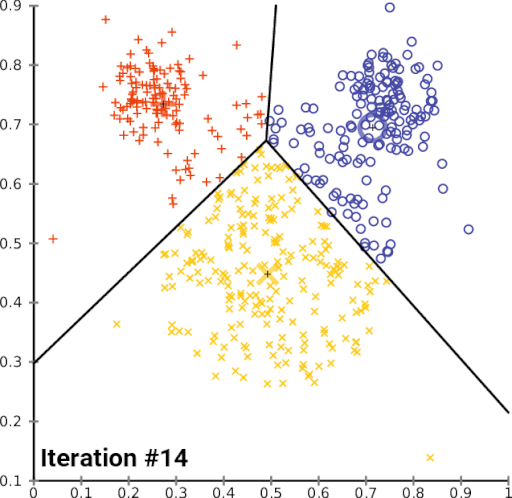
El algoritmo de aprendizaje no supervisado consta de los siguientes pasos:
- Inicialización: Cuando se escoge el número de grupos k, se establecen los k centroides en el espacio de los datos.
- Asignación: Cuando se asigna los objetos a su centroide más cercano.
- Actualización: Cuando se actualiza el centroide según el promedio de los objetos a los que pertenece.
EL algoritmo de aprendizaje no supervisado, gráficamente se podría definir que k-means agrupara datos con las mismas características.